
정규표현식이란?
특정한 규칙을 가진 문자열의 집합을 표현할 때 사용하는 형식 언어입니다.
주로 문자열의 특정 부분을 찾거나, 다른 문자열로 대체하거나, 특정 문자열을 추출할 때 사용합니다.
정규표현식은 다른 말로 정규식, Regexp, Regex라고 불리기도 합니다.
/^[\w.%+\-]+@[\w.\-]+\.[A-Za-z]{2,3}$/ig이것이 정규식의 모습입니다.
이메일 패턴을 간단하게 표현한 정규식인데, 처음보면 정말 무슨 소리인지 파악하기 힘들 겁니다.
하지만 개발자는 많은 자연어 속에서 특정 문자를 추출하고 가공하고 수정할 수 있어야 합니다.
불규칙한 자연어 속에서 특정 패턴을 찾아 처리하려면, 일반적으로 if문을 사용합니다.
하지만 if문을 그렇게 사용하다간 if 속에 if, 그 속에 if, 또 안에 if, 또 if.. if 지옥에 빠질 겁니다.
만약 정규식 사용법을 안다면, 그런 걱정할 필요 없습니다. 대신 가독성이 난해한 정규표현식을 알아야 합니다.

모르면 정말 어려운 정규식이지만, 알면 생각보다 쉽고 정말 좋고 편리합니다.
정규표현식 구성
1. 구분문자
정규식과 일반 문자열을 구분하기 위한 문자. javascript에서는 주로 /를 사용합니다.
2. 메타문자
정규식에서 일정한 의미를 가지고 사용되는 특수문자를 메타 문자라고 합니다.
3. 리터럴
정규식에서의 의미가 없는 문자 그대로 사용되는 문자들을 말합니다.
4. 플래그
정규식 패턴과 문자를 대조 & 검색 방법을 정의합니다.
정규식 플래그는 i, g, m, s, u, y 등이 있습니다.

정규표현식 문법 종류
문자 클래스 (Character classes)
문자 클래스는 문자 패턴을 찾을 때 사용합니다.
어떠한 문자가 포함된다, 포함되지 않는다. 어떤 문자만 찾는다 등등 문자 패턴을 구성할 때 사용합니다.
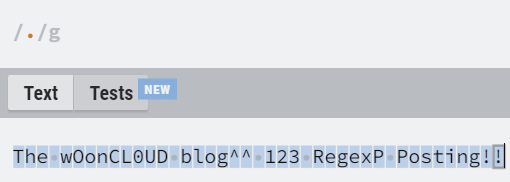
| . | 개행을 포함한 모든 글자. \n은 제외 |
| \w | ASCII 워드 문자. [a-zA-Z0-9]와 같다. |
| \d | 모든 ASCII 숫자. [0-9]와 같다. |
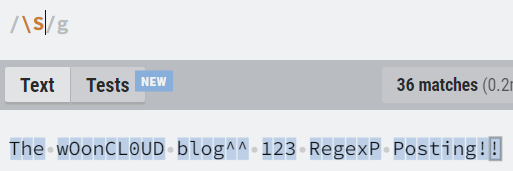
| \s | 모든 유니코드 공백 문자. |
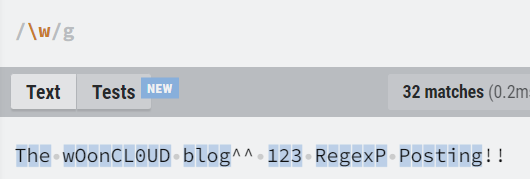
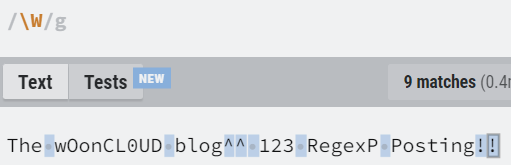
| \W | ASCII 워드 문자가 아닌 모든 문자. [^a-zA-Z0-9]와 같다. |
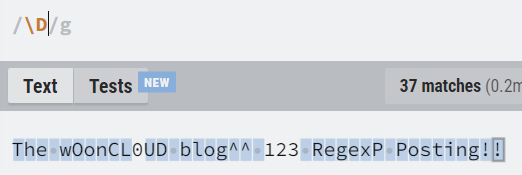
| \D | ASCII 숫자가 아닌 모든 문자. [^0-9]와 같다. |
| \S | 유니코드 공백 문자가 아닌 모든 문자. |
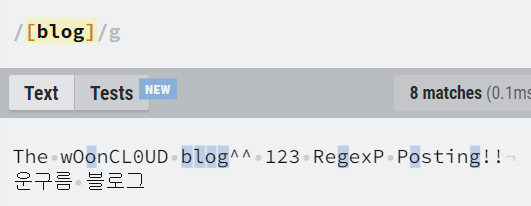
| [abc] | a 또는 b 또는 c |
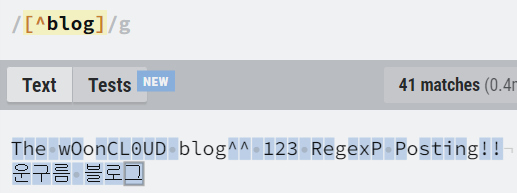
| [^abc] | a 또는 b 또는 c 포함하지 않음 |
| [a-g] | a부터 g 사이의 글자 |
| [ㄱ-ㅎㅏ-ㅣ] | 한글 자,모음 |
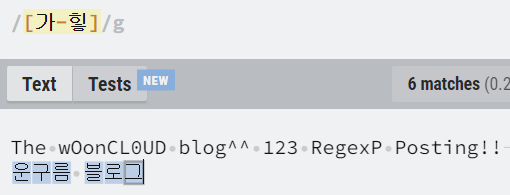
| [가-힣] | 한글 |


앵커 (Anchors)
앵커는 어떤 문자와 매치시키는 용도로 사용하지 않습니다.
앵커는 정규식 패턴 맨 앞과 맨 뒤에 위치하는데, 정규식 매치 위치를 고정하는데 사용합니다.
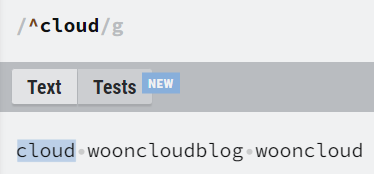
^가 있으면 문자열 시작부터 정규식 패턴과 일치해야 true입니다.
만약 문자열 맨 앞에 정규식과 일치하지 않는 문자가 있다면, 그 문자열은 전부 false입니다.
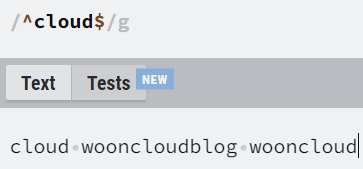
| ^abc$ | ^부터 $까지의 모든 문자열이 패턴과 일치해야 함. |
| ^abc | 문자열 시작부터 패턴과 일치해야 함. |
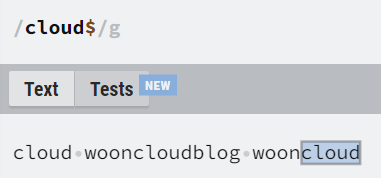
| abc$ | 문자열 마지막은 패턴과 일치해야 함. |
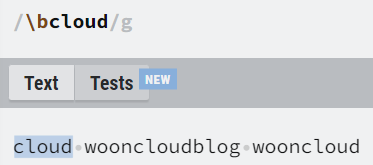
| \b | word boundary를 표현하며 단어의 경계를 나타냄 의미한다. |
| \B | non word boundary를 표현하며 단어의 경계가 아닌 곳을 의미한다. |
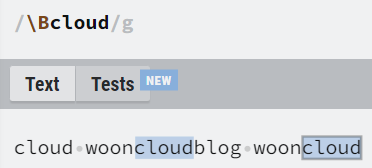
이스케이프 문자 (Escaped characters)
보통 개발할 때 이스케이프 문자인 \n, \r \t \\ 등을 많이 사용합니다.
이 이스케이프 문자는 정규식에서도 똑같이 사용되는데, 정규식에서는 정규식을 구성하는 메타문자를 리터럴로 표현하고 싶을 때, 이 이스케이프 문자를 사용합니다.
| \. \* \\ | 정규식 메타문자와 겹치는 특수문자를 표현할 때, 사용하는 이스케이프 문자를 사용함. (\. \* \\ \- \+ \[ \] \( \) \{ \} \? \: \= \! \| 등등이 있다.) |
| \t | tab (탭) |
| \n | linefeed (줄바꿈) |
| \r | carriage return (캐리지 리턴) |
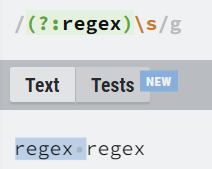
그룹(Groups)
소괄호를 이용하면 정규식 일부 패턴을 그룹화할 수 있습니다.
이 정규식 그룹은 그냥 그룹화하는 기능 외에 그룹 캡쳐 기능이 있습니다.
정규식 그룹은 번호가 매겨진 캡처 그룹을 생성하고, 괄호 안에 정규식 부분과 일치하는 문자열을 저장합니다.
그 캡처 번호를 사용하여 문자열 부분을 불러와 사용할 수 있습니다.
✅ 주의할 점은 캡처에 정규식 패턴이 저장된다고 착각할 수 있습니다.
캡처는 패턴으로 찾은 문자열을 저장하지, 그 그룹의 패턴을 다시 가져와 사용하는 것이 아닙니다.
그룹 앞에 ?:를 붙이면 캡처를 저장하지 않는 그룹도 만들 수 있습니다.
| (abc) | 캡쳐를 사용하는 그룹 |
| \1 | 그룹1 의 캡처를 사용함. |
| (?:abc) | 그룹이지만 캡쳐를 저장하지 않음. |
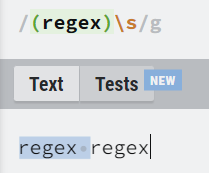
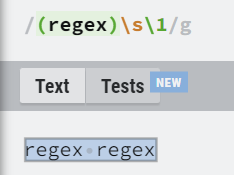
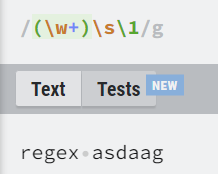
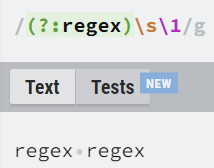
그룹을 만든 후 \1를 사용하면 \1자리엔 regex라는 글자가 있는 것과 같습니다.
3번째 사진을 보면 \w+를 사용했음에도 그룹 1의 캡처가 뒤의 asdaag를 찾지 못하는 모습을 볼 수 있습니다.
이것은 캡처에 저장되는 것이 정규식 패턴이 아닌 그룹과 매칭 된 문자열을 저장한다는 점을 알 수 있습니다.
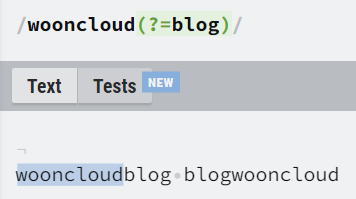
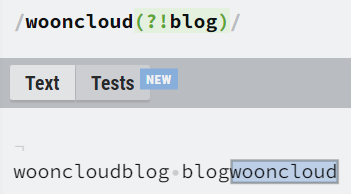
전후방탐색자 (Lookaround)
전후방탐색자는 특정 문자를 찾을때 앞뒤에 어떤 문자가 오는지 찾을 수 있습니다.
하지만 간혹 후방탐색자 (Lookbehind)는 특정 언어에서만 사용되는 경우가 많습니다. 사용하지는 언어가 후방탐색자를 지원하는지 알아보고 사용하면 좋을 것 같습니다.
| 123(?=abc) | (전방탐색자) 123을 찾는데 뒤에 abc가 오는 123을 찾음 |
| 123(?!abc) | (전방탐색자) 123을 찾는데 뒤에 abc가 안오는 123을 찾음 |
| (?<=abc)123 | (후방탐색자) 123을 찾는데 앞에 abc가 오는 123을 찾음 |
| (?<!abc)123 | (후방탐색자) 123을 찾는데 앞에 abc가 안오는 123을 찾음 |
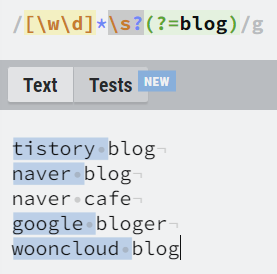
수량자 (Quantifiers)
어떤 정규식 패턴이 얼마나 반복되는지에 대한 패턴을 정의할 때 사용합니다.
수량자는 탐욕 수량자(Greedy Quantifiers)와 게으른 수량자(Lazy Quantifiers) 2가지 특징을 추가적으로 가지고 있습니다.
탐욕 수량자는 수량자 패턴에 만족하는 최대한의 문자열을 찾고, 게으른 수량자는 수량자 패턴에 만족하는 최소한의 문자열을 찾습니다.
| a* | a가 없거나 다수 |
| a+ | a가 1개 또는 그 이상 |
| a? | a가 없거나 1개 있거나 |
| a{5} | a가 5개여야 함 |
| a{1,3} | a가 1~3글자 |
| a{2,} | a가 2개거나 그 이상 - 탐욕 수량자 (Greedy Quantifiers) |
| a+? or a{2,}? | 다음 조건에 최소 조건 매치 - 게으른 수량자 (Lazy Quantifiers) |
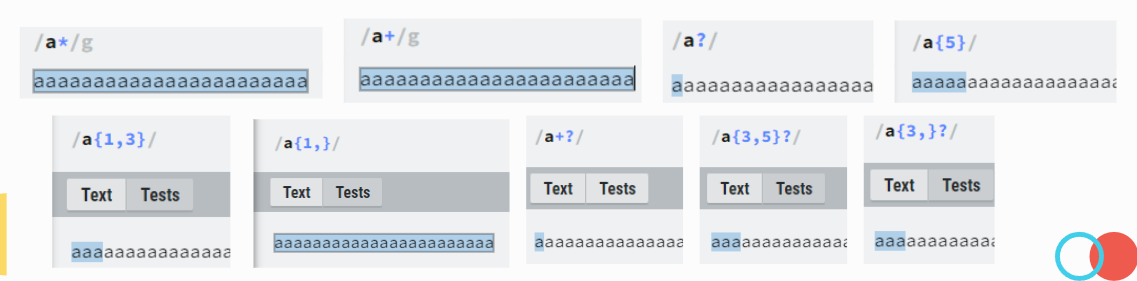
선택자 (Alternation)
선택자는 다양한 정규식 패턴 중 만족하는 패턴을 선택할 수 있도록 해줍니다.
선택자 양쪽에는 리터럴을 넣으셔도 되고, 정규식 패턴을 넣으셔도 됩니다.
OR 이랑 비슷하다고 보시면 되겠습니다.
| ab|cd | ab 또는 cd인 것을 찾는다. |
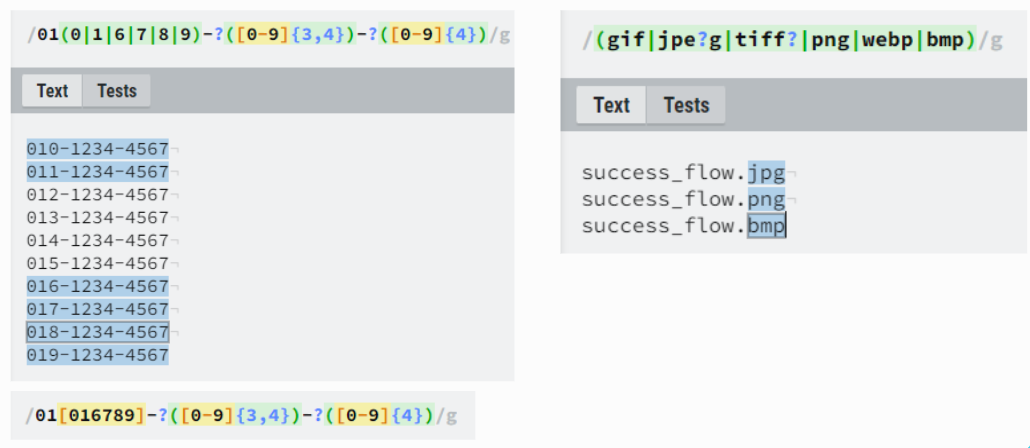
플래그 (Flag)
플래그는 정규식 구분자 맨 마지막에 붙는 문자입니다.
플래그는 정규식 검색 옵션을 설정하는 문법이라고 보시면 되겠습니다.
맨 마지막에 어떤 플래그가 오냐에 따라 정규식 검색 방법이 달라집니다.
| g | 검색에 패턴을 만족하는 모든 글자를 찾음. |
| i | 검색에 대소문자 구분하지 않음 |
| m | 문자열의 행이 여러개일 경우 행 별로 구분해서 패턴을 검색. (각 행 별로 패턴이 있는 경우 사용) |
| s | dot(.) 문자가 개행(\n)을 포함한 모든 문자에 패턴이 되도록 'dotAll' 모드 활성화 |
| u | 유니코드 패턴을 사용 |
| y | 문자 내 특정 위치에서 검색을 진행하는 'sticky' 모드 활성화. (자바스크립트에서 ) lastIndex를 사용함. |
flag - m 사용 예시
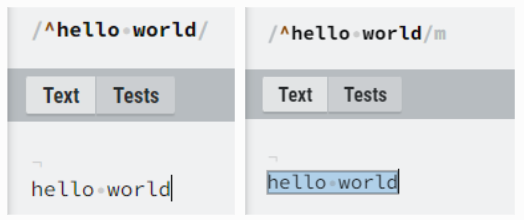
flag - s 사용 예시
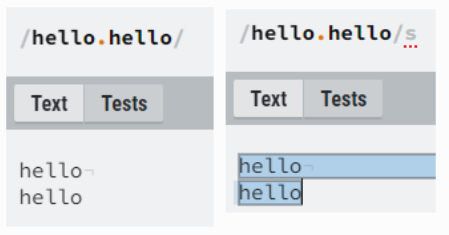
flag - y 사용 예시
var test = 'ab?de';
test = test.replace(/./, '#');
console.log(test);
// #b?de
// ------------------------------
var test = 'ab?de';
regExp.lastIndex = 2;
test = test.replace(/./y, '#');
console.log(test);
// ab#de
각 언어별 정규식 사용 방법
javascript
자바스크립트로 정규식을 사용하는 방법이 많습니다.
이번 포스트에서 다루면 길어질 것 같아 다른 포스트로 다루어보겠습니다.

// new RegExp('정규식', '플래그');
let regExp1 = new RegExp('hello', 'g');
// /정규식/플래그;
let regExp2 = /hello/g;
RegExp.test()
해당 정규식을 검색 용도로 활용한 예시입니다.
정규식 조건이 참인지 거짓인지 판별할 수 있습니다.
/hello/g.test('hello, world');
// true
/hello/g.test('Hello, world');
// false
Java
정규식 지원 String 메소드
| Method | Description |
| String.matches(regex) | String이 regex와 일치하면 true 리턴 |
| String.split(regex) | regex와 일치하는 것을 기준으로 String을 분리하여 배열로 리턴 |
| String.replaceFirst(regex, replacement) | regex와 가장 먼저 일치하는 것을 replacement로 변환 |
| String.replaceAll(regex, replacement) | regex와 일치하는 모든 것을 replacement로 변환 |
Pattern Class
Regex는 "\d"와 같이 String으로 표현할 수 있습니다.
Pattern은 컴파일된 Regex라고 표현합니다.
Matcher Class
Matcher는 match operation을 수행하는 클래스입니다.
Matcher는 다음과 같이 Pattern 객체로부터 생성됩니다.
인자로 패턴을 찾을 문자열을 전달합니다.
매치된 결과는 matcher 객체에 담겨 있습니다.
Pattern pattern = Pattern.compile("\\bship\\b");
Matcher matcher = pattern.matcher("A ship-shipping ship ships shipping-ships");위의 코드를 실행하면 matcher 객체에 ship 하나만 추출되어 있는 것을 볼 수 있습니다.
postgresql
정규식 일치 연산자: ~, ~*, !~, !~* (POSIX-Style Regular Expressions)
보통 SQL where 절에서 사용하는 POSIX 스타일 정규식 사용법입니다.
-- ~ 연산자 : 정규 표현식과 일치, 대소문자 구분.
select * from user_info where email ~ '[\w\d]*_[\w\d]*'; -- 언더바 문자(_)가 있는 이메일 찾기
select * from user_info where email ~ '.*@(naver.com)$'; -- 뒤에 네이버 주소가 오는 이메일 찾기
-- ~* 연산자: 정규 표현식과 일치, 대소문자를 구분하지 않음.
select * from user_info where email ~* '.*@(NAVER.COM)$';
-- !~ operator: 정규식과 일치하지 않음, 대소문자 구분
select * from user_info where email !~ '.*@(naver.com)$';
-- !~* operator: 정규식과 일치하지 않음, 대소문자를 구분하지 않음.
select * from user_info where email !~* '.*@(NAVER.COM)$';
regexp_replace 사용
select절에서 특정 컬럼의 문자열을 정규식으로 찾아 대체할 때 사용하는 함수입니다.
regexp_replace(대상 문자열, 정규식 패턴, 바꿀 문자열, 검색 시작 위치 (default : 1), 바꿀 횟수 (0이면 모든 값 대체), flag (c, i, m 등등))-- user_info 테이블에 email에 @ 앞부분 아이디만 추출
-- 그룹 캡처 사용.
select regexp_replace(email, '(.*)(@.*)', '\1')
from user_info;
정규식 사용에 유용한 사이트
1. 정규식 테스트 사이트
RegExr: Learn, Build, & Test RegEx
RegExr is an online tool to learn, build, & test Regular Expressions (RegEx / RegExp).
regexr.com
2. 정규식 시각화 사이트
Regexper
regexper.com
3. 정규식 테스트 사이트
regex101: build, test, and debug regex
Regular expression tester with syntax highlighting, explanation, cheat sheet for PHP/PCRE, Python, GO, JavaScript, Java, C#/.NET.
regex101.com
IDE에서 replace 꿀팁
대부분 IDE에서 문자열 찾기 (Ctrl + F)를 사용할 때, 정규식을 활용하여 찾을 수 있습니다.
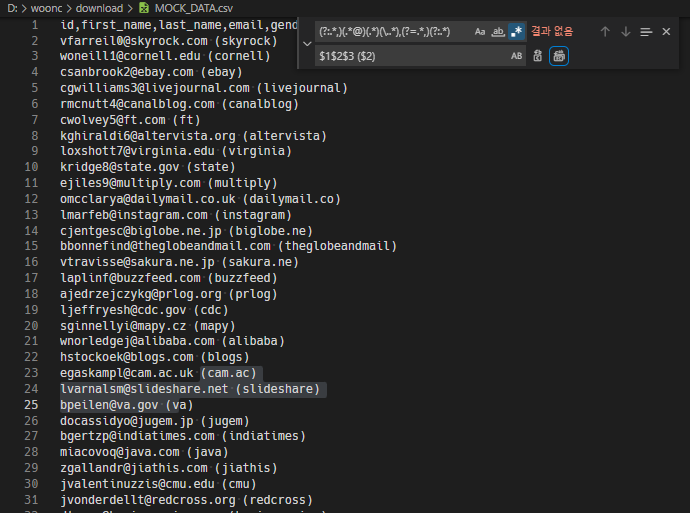
만약 여러분에게 아래와 같은 데이터들이 있다고 생각합시다.
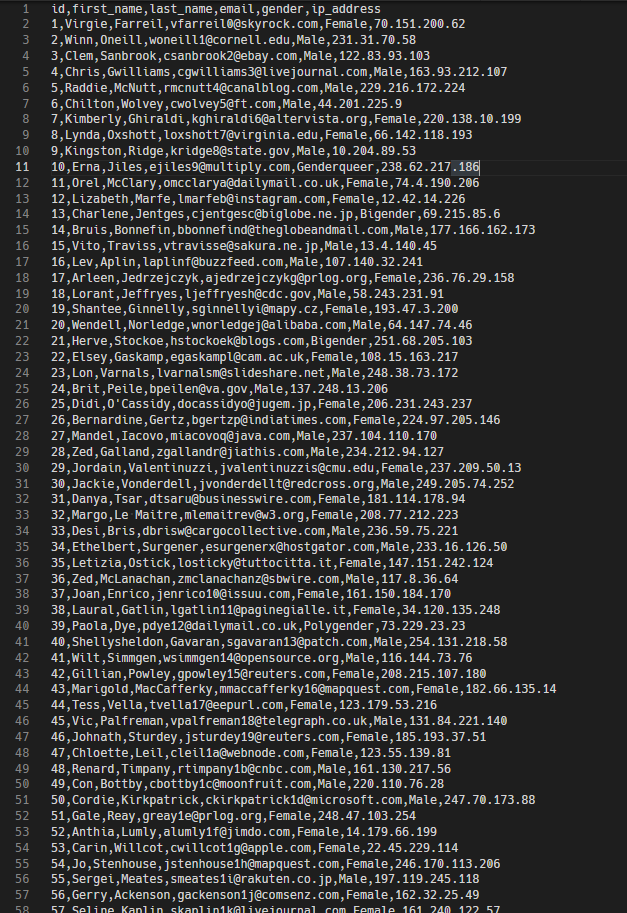
이 데이터에서 여러분들이 필요한 내용은 이메일 주소와 이메일 주소에 적힌 이메일 서비스 이름입니다.
예시)
vfarreil0@skyrock.com 라는 이메일이 있다고 가정하면
vfarreil0@skyrock.com 라는 이메일 주소와 skyrock 이라는 이메일 서비스의 이름입니다.
답 : vfarreil0@skyrock.com (skyrock)
여러분은 이런 데이터를 가공하고 싶으시면 어떻게 하시겠습니까?
엑셀을 잘 사용하는 사람은 이 파일을 엑셀로 열어서 함수를 통해 데이터를 추출할 수 있겠지만,
우리 개발자는 VS Code를 잘 사용합니다.
정규식과 VS Code를 통해서 데이터를 한번 가공해보겠습니다.
과정
모카루에서 만든 더미데이터
VS Code에서 Ctrl + F 를 누르면 서치 도구가 열립니다.
서치 도구 앞에 > 모양 버튼을 누르면 찾은 내용을 변경할 수 있습니다.
그리고 오른쪽에 .* 모양의 아이콘을 클릭하면 정규식으로 문자를 찾을 수 있습니다.

자 이제 더미데이터를 정규식으로 원하는 부분만 찾아 바꾸는 방법을 알아보겠습니다.
우리가 사용할 정규식은 다음과 같습니다.
(?:.*,)(.*@)(.*)(\..*),(?=.*,)(?:.*)
정규식의 크룹 캡쳐 기능으로 아래의 데이터 한 줄을 다음과 같이 변경할 수 있습니다.
VS CODE와 대부분 IDE에서 그룹 캡처를 $1, $2 ... 등으로 추출할 수 있습니다.

결과
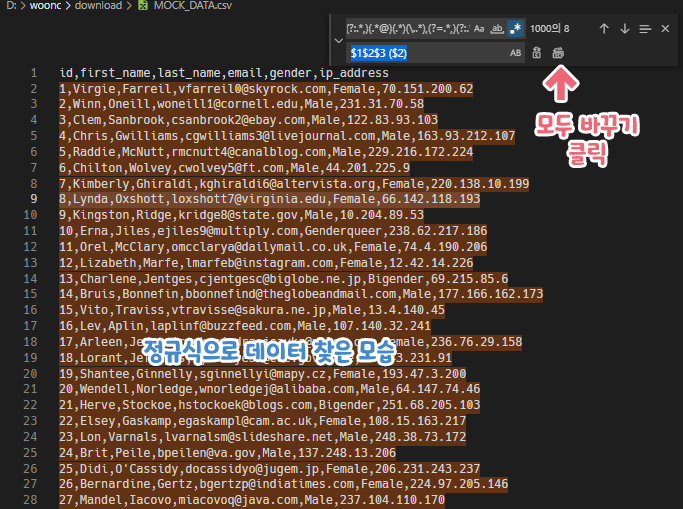
이렇게 정규식에 익숙해진다면, 문자열 찾기나 가공은 더욱 편해질 것입니다.
참고 사이트
'개발 아카이브 > 개발 관련 지식' 카테고리의 다른 글
| 정규식을 이용한 공격 - ReDos (0) | 2022.12.24 |
|---|---|
| Postman 대신 사용하는 VS Code API Test Extention - Thunder Client (1) | 2022.11.13 |
| gitignore 파일을 쉽게 만들어주는 사이트 gitignore.io (0) | 2021.09.01 |
| CI/CD 기본 개념 정리와 툴 (0) | 2021.09.01 |
| MarkDown을 편하게 작성하기 위한 도구들 (0) | 2021.04.29 |